Reference
https://arxiv.org/html/2412.19437v1
https://arxiv.org/abs/2405.04434
https://arxiv.org/abs/2401.06066
https://zhuanlan.zhihu.com/p/16730036197
https://dataturbo.medium.com/deepseek-technical-analysis-2-mla-74bdb87d4ad2
1. Intro
TODO
대충 우리 이전 DeepSeek-V2에서 사용한 Multi-head Latent Attention(MLA라고 약칭)으로 효율적인 추론을 가능하게 했고, DeepSeekMoE로 저렴한 훈련을 가능하게 만들었다고 함.
소위 말해 검증된 아키텍처.
이 두 핵심 모델 아키텍처에 더해서, 로드밸런싱을 위한 Auxilary-loss-free 전략(번역하자면 보조 손실 제거)와 Multi-token prediction 또한 사용해 벤치마크 성능 증가를 얻었다고 한다.
또한, 효율적인 훈련을 가능하기 위해 FP8 mixed precision training 등을 활용했다고 한다.
DeepSeek-V3 모델은 14.8T 으로 훈련되었으며, 이 과정에서 loss 스파이크나 롤백이 필요하지는 않았다고 한다.
context length 증가는 2단계로 이루어졌으며, 처음에는 32K, 다음에는 128k로 확장함. 이와 함께 흔히 진행되는 SFT, 그리고 RL을 활용했다 함.
2. Architecture
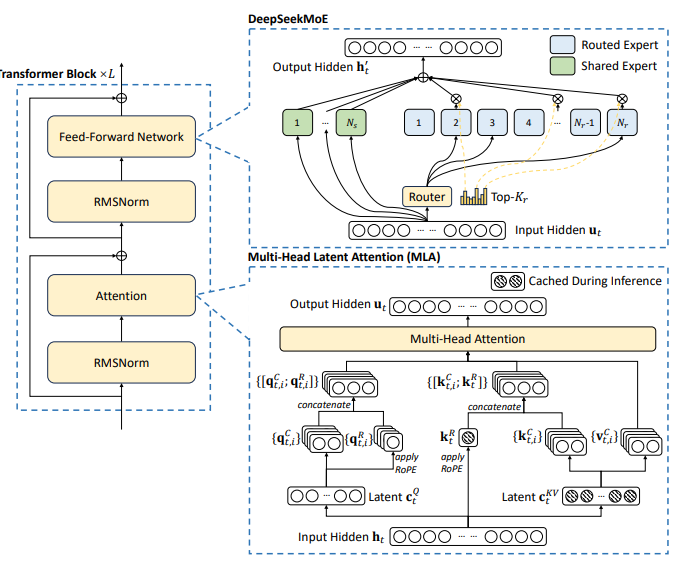
2.1. Multi-head Latent Attention
일반적인 트랜스포머 모델은 주로 Multi-head attention을 활용한다. 허나, 이를 사용할 시 훨씬 더 큰 KV 캐시에 의해 생성(추론) 병목이 생긴다.
KV 캐시를 사용하지 않을 경우, 시퀀스 길이 N에 대해 \(O(N^3)\) 까지 복잡도가 증가하여 빠른 추론에는 필수적이지만 이에 대한 tradeoff로 소모하는 VRAM의 양이 매우 커 사용하던 안하던 간 결국 operation 횟수와 메모리의 tradeoff가 필수적으로 일어나게 된다.
KV 캐시를 줄이기 위해, MQA와 GQA와 같은 방법들이 제시되었으나 해당 방법을 사용할 경우 MHA보다 성능이 떨어진다.
Multi-head Latent Attention은 로우랭크 key-value joint 압축으로 MHA보다 나은 성능을 가지며, KV 캐시의 크기를 크게 감축한다.
2.1.1. Preliminaries: 일반 Multi-Head Attention
먼저 MHA 메커니즘에 대한 이해가 필요하다. 다음과 같은 변수들을 정의하고 이를 바탕으로 설명하겠다.
- \(d\): 토큰 임베딩 차원 수
- \(n_h\): 어텐션 헤드의 수
- \(d_h\): 어텐션 헤드당 차원 수 (일반적으로 \(d_h = \frac{d}{n_h}\), 그리고 \(d_h < d\))
- \(h_t \in \mathbb{R^d}\): 토큰 \(t\)의 어텐션 인풋. 한 토큰만 집중한 것으로, 벡터임
MHA는 토큰 \(t\)의 표현 \(h_t\)를 세 매트릭스 \(W^Q, W^K, W^V \in \mathbb{R^{d_h n_h \times d}}\)에 곱해 \(q_t, k_t, v_t \in \mathbb{R^{d_h n_h}}\) 으로 바꾼다.
이 \(q_t, k_t, v_t\)는 \(n_h\) 헤드만큼 쪼개지게 되고, 각 헤드당 차원 수는 \(d_h\)이다.
이제 평범하게 Scaled-dot attention, 즉 Softmax\((\frac{QK^T}{\sqrt{d_k}})V\) 를 각 헤드에 대해서 수행하면 토큰 \(t\)에 대해 \(n_h\) 개의 \(\mathbb{R^{d_h}}\)벡터를 얻고, 이를 concat 해 최종적으로 원래 토큰 임베딩의 수 \(d\)를 가지도록 돌려놓는다.
이 MHA를 사용할 경우, 필요한 KV 캐시는 토큰당 \(2n_hd_hl\) (\(l\)은 레이어 수)를 소모한다. 이는 배치 크기와 시퀀스 길이를 제한하는 병목이다.
실제 추론을 진행할 때의 예시를 확인해보기 위해, 배치 크기를 \(b\), 시퀀스 길이를 \(s\)로 두었을 때 KV 캐시 메모리 계산식은 다음과 같다.
\[ 2 \times l \times b \times(n_h \times d_h \times s) \times {dtype} \]
레이어 수, 배치 수, 시퀀스 길이 등이 잔뜩 곱해지므로 VRAM을 정말 많이 소비하게 하는 주 화신으로, 막상 오픈소스로 시퀀스를 길게 만들어놓는 모델도 이것때문에 가져다 쓰는것마저도 힘들다.
2.1.2. 로우랭크 Key-Value Joint 압축
MLA의 핵심으로, Keys와 Value를 서로 joint하게 묶어 압축을 진행해 KV 캐시를 줄인다.
\[ c^{KV}_t = W^{DKV}h_t \\ k^C_t = W^{UK}c_t^{KV} \\ v^C_t = W^{UV}c^{KV}_t \]
Where…
\[ c^{KV}_t \in \mathbb{R}^{d_c} (d_c << d_h n_h)\\ W^{UK}, W^{UV} \in \mathbb{R^{d_h n_h\times d_c}} \]
다음과 같이, 토큰 \(t\)에 대해서 Key, Value 캐시를 각각 저장하는 것이 아닌 어텐션 인풋을 한개의 다운프로젝션 매트릭스를 거쳐 훨씬 더 작은 \(d_c\)의 벡터로 압축한다.
이 방법을 활용하게 되면 MLA에서 토큰당 캐시되는 KV 캐시는 \(d_cl\)개로 크게 감소하게 된다.
실 추론에서 사용할때는, 업프로젝션 매트릭스 \(W^{UK},W^{UV}\)에 통과시켜 각각 Key, Value로 활용되며 \(W^{UK}\)는 \(W^Q\)와 통합 가능하고, \(W^{UV}\)는 \(W^O\)에 흡수시킬 수 있으므로 별도로 필요한 compute 또한 없다.
이는 한 토큰에 대해서 동일한 어텐션 인풋을 기반으로 \(W^K, W^V\)를 통과시켜 사용하는 어텐션 구조를 영리하게 사용한 일종의 꼼수이다.
이번엔 활성화된 메모리의 크기를 줄이기 위해, KV 캐시를 감소하는데에는 도움이 되진 않지만 Query도 비슷한 방식으로 압축을 진행한다. 이유는 나중에.
\[ c^Q_t = W^{DQ}h_t\\ q^C_t = W^{UQ}c_t^Q \]
\[ c^Q_t \in \mathbb{R^{d_c^{\prime}}}\\ W^{DQ} \in \mathbb{R^{d_c^{\prime}\times d}}\\ W^{UQ} \in \mathbb{R^{d_h n_h \times d_c^{\prime}}} \]
\(d_c^{\prime} << d_hn_h\)
2.1.3. 디커플된 RoPE
DeepSeek 67B 이후, DeepSeek-V2 또한 RoPE를 활용한다.
하지만, 기존 RoPE는 위에 기술한 MLA를 활용해 KV를 압축하는 것과 호환되지 않기에 단순하게 적용할 수는 없음.
위에 기술된 방법으로 각 토큰당 임베딩을 낮은 차원으로 축소해 들고 있으면 결국엔 원래 임베딩 차원으로 돌려놓아야 하는데, 이때 활용되는 업프로젝션 매트릭스 \(W^{UK}\). \(W^{UV}\)를 Scaled-dot multi head attention을 계산할때 사용되는 \(W^Q\)와 마지막 출력 프로젝션 \(W^O\)에 각각 행렬곱해두면 내적에서 결합법칙이 성립하기 때문에 기존 어텐션에서 추가적인 단계의 연산이 최소한 발생하게 된다.
허나, RoPE를 이용하게 되면 결합법칙이 더이상 성립하게 되지 않는다.
\[ RoPE(c^{Q}_t)W^{UQ} \neq RoPE(c^Q_t \cdot W^{UQ}) \\ RoPE(c^{K}_t)W^{UK} \neq RoPE(c^K_t \cdot W^{UK}) \]
따라서 RoPE를 단순하게 압축된 시퀀스에 적용해버리게 되면 문제가 발생하게 된다. 압축된 시퀀스의 임베딩에 적욘하는 것은 순서상 맞지 않기 때문이다.
이를 해결하려면 별 수 없이 업프로젝션을 먼저 해야 하는데, 여기서 흡수가 불가능해진다는 말이 나온 것이다.
하지만 RoPE를 사용하지 않으면 포지셔널 임베딩을 제공할 수 없기에, 이는 굉장히 난처한 상황이다. 이를 어떻게 해야 할까? Deepseek-V2는 Query, Key에 대해 별도로 압축된 토큰 임베딩을 업프로젝션하고 RoPE를 적용, 이를 그대로 concat한다고 한다.
RoPE를 별도로 업프로젝션된 Q, K에 적용하고, 이걸 또 압축된걸 업프로젝션한 거에다가 이어 붙이는거다. 이를 진행하게 되면 각 토큰당 임베딩이 원본보다 커지게 된다. 하지만 걱정할 필요는 없다. Scaled-Dot Multi-head attention을 적용하면서 Q와 K를 내적하기 때문에 차원은 \(\text{len}(seq) \times \text{len}(seq)\) 로 돌아오며, 이는 다행히도 V 행렬과 곱해질 수 있다.

이 방식을 진행하게 되면 더 이상 RoPE 적용으로 내적의 교환법칙이 불성립하지 않아 \(W^{UK}\)는 \(W^{UQ}\)로 흡수(미리 내적해두기), \(W^{UV}\)는 \(W^{O}\)로 흡수(내적)시켜 추론 과정에서 추가적인 연산을 최소화시킬 수 있다.
2.2 DeepSeekMoE
2.2.1. Preliminaries: Mixture-of-Experts in Transformer
일단 이 글을 작성하는 본인 또한 MoE에 특별하게 관심을 가지지 않아서, 기본적인 MoE에 대해 기술하겠다.
기본 트랜스포머 기반 language model은 Self attention과 FNN으로 구성되어있는 트랜스포머 Block을 여러개 적층하는 방식인데, MoE는 FFN을 MoE 레이어로 일부 치환하는 방법으로 만들 수 있다고 한다. MoE 레이어는 여러 전문가(experts)로 구성되는데, 각 전문가는 FFN과 동일한 구조를 가지고 있다.
그리고, 각 토큰은 한개 내지 두개의 전문가에 할당된다. 대충 수식으로 만들어 준걸 봐보자.
\[ u^l_{1:T} = \text{SelfAttn}(h^{l-1}_{1:T}) + h^{l-1}_{1:T} \]
\[ h^l_t = \text{FFN}(u^l_t) + u^l_t \]
\[ h^l_t = \sum_{i=1}^{N} (g_{i,t} \text{FFN}_i(u^l_t)) + u^l_t \]
\[ g_{i,t} = \begin{cases} s_{i,t}, & s_{i,t} \in \text{TopK}(\{s_{j,t} | 1\le j \le N\}, K) \\ 0, & \text{otherwise} \end{cases} \]
\[ s_{i,t} = \text{Softmax}_i({u^{l}}^{T}_t e^l_i) \]
각 변수는 다음을 나타낸다.
- \(T\): 토큰의 갯수(시퀀스 길이, 전체 토큰을 의미함.
- \(l\): 레이어 번째수.
- \(h^{l-1}_{1:T}\), \(h^{l}_{1:T}\): 각각 \(l-1, l\)번째 레이어의 토큰 hidden state.
- \(u^{l}_{1:T}\): 이건 \(l\)번째 레이어에서의 self-attention과 잔차연결까지 거친것(어텐션 compute 이후 시퀀스의 값)
- \(s_{i,t}\): 토큰 t와 각 FFN expert의 중심(centroid)와 softmax를 비교해 토큰당 expert 간 유사도를 계산한다. 이를 진행하고 나면 각 토큰 t가 어느 expert로 routing 되어야 하는지 결정할 수 있다.
- \(g_{i_t}\): 위 \(s_{i,t}\)를 top_k 샘플링을 통해서 상위 2개의 expert로 routing 하는 gate이다. top_k 샘플링으로 제외된 라우터들의 경우, FFN을 통과해도 그 값이 반영되지 않도록 0으로 고정한다.
\[ h^l_t = \sum^{N}_{i=1}{(g_{i,t}FFN_i(u^l_t))+u^l_t} \]
여기서 저 \(g_{i,t}\)를 활용해서 선택되지 않은 두개의 expert FFN은 무시되고, 나머지는 각각의 softmax 확률에 따라 곱해져 더해진다(weighted sum). 더해지는건 잔차연결.
생각보다 별게 없어서 의외였다. 이제 DeepSeekMoE의 구조를 알아보도록 하자.
2.2.2. DeepSeekMoE 1탄: 잘게 다진 Expert들
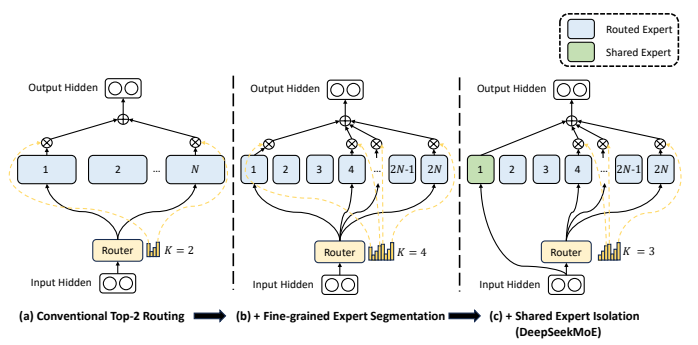
DeepSeekMoE는 각 Expert가 훨씬 더 자신의 분야에만 집중할 경우의 포텐셜을 끌어내기 위해 꾀하는 방식이다.
일반적인 MoE에서, Expert의 갯수는 그리 많지 않은 편이다. 대부분 8개 이하의 Expert로 구성되어있는데,(https://huggingface.co/alpindale/WizardLM-2-8x22B) 이는 다소 적은 편이라고 할 수 있다.
당장 우리나라의 도서 분류 체계도 10개로 책을 분류하는데, 8개의 expert 수가 전부라면 이 expert는 필연적으로 매우 넓은 분야의 지식을 파라미터에 습득하게 될 것이고, 동시에 활성화되기는 힘들것이다. 이를 해결하기 위해 각 토큰이 더 많은 expert로 라우팅된다면, 더 다양한 지식이 쪼개져 적절한 expert에 학습될 것이다.
이를 적용시키기 위해서 일반적인 MoE에서의 expert 각각을 m개의 더 작은 expert로 쪼갠다고 한다. 이때, 각 FFN의 hidden 차원 또한 \(\frac{1}{m}\)으로 감소시킨다. 이때 각 expert가 작아지기 때문에, 활성화된 expert 또한 m배만큼 더 증가시킨다. 계산 방식은 기존 MoE와 똑같은 방식으로,
이는 가능한 조합의 증가가 가능하게 만들기에 더 유리한데, 일반적인 top-2 routing 전략은 가능한 조합의 수가 120개인 반면, m=4일때는 64개에서 8개를 선택하는 조합으로 44억개의 가능한 조합의 수가 있다. 더 다양한 expert의 조합이 가능한 만큼, 더 특화된 응답을 내놓을 수 있게 된다.
2.2.3. DeepSeekMoE 2탄: 공유 Expert의 분리
기존 라우팅 전략에서, 서로 다른 expert에 들어가는 토큰들은 일반적인 지식이 필요한 경우가 있을 수 있다. 이로 인해, 많은 expert들은 서로 공유된 지식을 각 파라미터에 보유할 수 있게 된다.
이는 expert의 본래 의도가 아니고, 반복된 지식이 여러 expert에 퍼져있게 되어 정상적으로 routing을 되지 못하게 방해할 수도 있다.
DeepSeekMoE는 이런 보편적인 지식을 처리하기 위해, \(K_s\)개의 공유 expert를 지정해준다. 이 공유 expert는 라우터와 관계없이, 항상 토큰들이 무조건 거치는 FFN이다.
\(K_s\)개를 뺀 나머지, 즉 \(mN - K_s\)개를 라우터를 활용해 top_k 샘플링으로 공유 expert가 아닌, 특화된 expert에 할당하는 방식이다
2.2.4. 로드밸런싱을 위한 loss
해당 보조 loss 함수들은 DeepSeek-V3에서 사용하지 않는다.
자동으로 학습된 라우팅 전략들은 다음과 같은 로드 임밸런스 문제에 봉착할 수 있다.
- 라우팅 무너짐
- 해당 문제는 모델이 항상 특정 몇개의 expert만 선택할 경우로, 이는 다른 expert이 훈련되는 것을 방해한다.
- 또한 사용되지 않는 expert가 존재하게 되어, 컴퓨팅 자원을 잡아먹고 활용되지 않을 수도 있다.
- 컴퓨팅 병목
- MoE 아키텍처는 VRAM을 많이 잡아먹는 특징이 있다. 활성화된 실제 파라미터 수는 적은 편이지만, 모델을 한개의 장치에 올리기는 무리다.
- 이로 인해, 멀티 디바이스(Multi-GPU 환경인듯)에서 로드 임밸런스는 병목 현상에 악영향을 끼칠 수 있다.
해당 문제를 해결하기 위해, 모델을 훈련할 때 추가적인 loss를 지정한다.
Expert 수준 밸런싱 loss
이는 앞에서 언급한 첫번째 문제를 방지하기 위한 것이다.
\[ \mathcal{L}_{ExpBal} = \alpha_1 \sum^{N^\prime}_{i=1} f_iP_i\\ f_i = \frac{N^\prime}{K^\prime T}\sum^T_{t=1}{𝟙}(\text{token}\space t\space \text{selects}\space \text{Expert}\space i)\\ P_i = \frac{1}{T}\sum^T_{t=1}s_{i,t} \]
해당 손실을 분석해보면, \(s_{i,t}\)는 softmax로 i번째 expert를 선택할 확률이므로 \(P_i\)는 전체 토큰 시퀀스에서 \(i\)번째 expert가 선택될 확률의 평균이고, \(f_i\)는 전체 선택 가능한(\(K_s\)의 항시 활성화 공유 expert를 제외한) expert 중에서 얼마나 많은 비율로 \(i\)번째 expert가 택해졌는지를 측정한다. 즉, expert \(i\)의 선택 빈도(frequency)임. \(\alpha_1\)은 하이퍼파라미터.
따라서, \(\mathcal{L}_{ExpBal}\)은 특정한 expert들이 계속 선택되는 것에 \(\alpha_1\) 만큼 곱한 값의 페널티를 부여하는 것으로 생각할 수 있다.
디바이스 수준 밸런싱 loss
이는 2번째 문제를 해결하기 위한 것이다. Expert들을 D개의 파티션 \(\{\mathcal{E}_1,\mathcal{E}_2,...,\mathcal{E}_D\}\)로 쪼개서, 각 파티션을 한개의 디바이스에 배포하는 형태인데, 이 손실 함수는 D개의 파티션들에 대해서 고르게 expert를 분산시키는 방식으로 모든 디바이스가 고르게 사용되는 로드밸런스를 돕는 loss 이다.
\[ \mathcal{L}_{\text{DevBal}} = \alpha_2 \sum_{i=1}^{D} f'_i P'_i, \\ f'_i = \frac{1}{|\mathcal{E}_i|} \sum_{j \in \mathcal{E}_i} f_j, \\ P'_i = \sum_{j \in \mathcal{E}_i} P_j \]
이 손실 함수는 한 파티션에서 많은 expert의 선택 빈도를 보이거나, 한 파티션에서 softmax가 높은 확률로 expert를 선택할 때 증가하게 된다.
\(\alpha_2\)는 하이퍼파라미터이다.
이상적인 상황이라면, 모든 파티션에서 고르게 expert를 일정한 확률로 선택할 때 해당 loss가 최소화 될 것이다.
DeepSeekMoE는 상대적으로 \(\alpha_1\)을 낮게 잡고, \(\alpha_2\)를 크게 잡아 적절하게 라우팅 무너짐 문제를 해결하고 비교적 강하게 고른 디바이스 활용을 추진한다.
커뮤니케이션 밸런싱 loss
DeepSeek-V2에서 추가된 내용으로, 위 디바이스 수준 밸런싱 loss는 단순히 디바이스 간 expert 가 활성화 되는 확률이 균등하게 만드는 것이 핵심이다.
즉, 특정 디바이스가 다소 많은 토큰을 받는다 하더라도, softmax에서 근소한 확률의 차이로 Top K 샘플링에 선택되었다면 OK 시켜버린다는 것이다.
이걸 막기 위해, 또 균등한 토큰을 각 디바이스가 처리할 때 최소가 되는 loss를 추가했다.
2.3. DeepSeek-V2, V3
이 부분에서는 DeepSeek-V2에서 업데이트되거나 그대로 가져와 DeepSeek-V3 에서 위 MLA, DeepSeekMoE에 추가로 사용한 방법들을 기술한다.
2.3.1. 토큰 Dropping 전략
위에 기술한 밸런스 loss들은 로드밸런싱에 도움이 되지만, 이는 엄격한 로드밸런싱을 보장하지 않는다. 이를 해결하기 위해서, 각 디바이스마다 평균 컴퓨팅 예산을 할당해주고, 이를 초과하는 가장 낮은 토큰 - expert와의 관계 점수를 가진 토큰들을 drop 시켜 완전히 무시한다.
또한, 항상 10%의 학습 시퀀스의 토큰을 절대 drop되지 않게 보존한다. 이는
- 디바이스간 연산이 불균형해지는 것을 엄격하게 제한
- 관계없는 토큰들의 연산을 제외하므로 더 효율적인 성능
을 이끌어내고, 추론과 학습 단계에서의 차이가 없이 같이 사용할 수 있게 된다.
2.3.2. 보조 손실 없는 로드밸런싱
2.2.4 에서 여러가지 보조 손실을 기술했다. 하지만, DeepSeek-V3에서는 추가로 진행된 MoE 연구로 인해 더 이상 2.2.4의 보조 손실들을 사용하지 않는다.
DeepSeek-V2의 후속 논문에 따르면, MoE의 라우터에서 보조 손실값을 활용할 경우 확실히 로드 밸런싱에 도움이 되는 것은 맞다. 허나, 이렇게 임의의 loss를 추가로 더해버리게 되면 language model의 loss가 묻혀버리게 된다. 즉, 모델이 정상적인 자연어를 출력하는 것을 학습시키는 기울기에 지대한 영향을 미치기에, 이를 해결하기 위해서 하이퍼파라미터 \(\alpha_1, \alpha_2\)를 또 감소시키면 로드밸런싱이 제대로 되지 않는 딜레마에 빠지게 된다.
그래서 손실 함수 없이 어떻게 로드밸런싱을 이룩했는지 봐보면… 학습 도중에 Softmax 결과값 밑장빼기다.
Top K 방식으로 샘플링해 expert로 라우팅 되는 과정에서, softmax를 활용해 각 토큰을 보내는 것이 게이트 함수의 역할인데, 학습 중간에 로드 imbalance가 관측되면 이 토큰→Expert를 담당하는 softmax에 더해지는 편향 값을 감소시켜 덜 가게 밑장빼기를 사용하는 것이다.
사람이 직접 수동으로 편향을 조절하는 방식이라서, 별도의 손실 함수의 활용 없이 해결할 수 있다…
2.3.3. 보완용 시퀀스-단위 보조 손실
2.3.2. 처럼 직접 디바이스의 utilization을 확인해 편향을 변경하는 방식은 대부분의 경우에서 확실하게 로드밸런싱을 보장합니다.
하지만, 추론 단계에서 여전히 시퀀스가 불균형하게 expert로 이동할 수 있으므로, 보완 손실을 사용해 고르게 시퀀스의 토큰들을 expert에 보낼 수 있도록 만든다.
\[ \mathcal{L}_{\text{Bal}} = \alpha \sum_{i=1}^{N_r} f_i P_i \]
\[ f_i = \frac{N_r}{K_r T} \sum_{t=1}^{T} \mathbf{1} \left(s_{i,t} \in \text{Topk}(\{s_{j,t} | 1 \leq j \leq N_r\}, K_r) \right) \]
\[ s'_{i,t} = \frac{s_{i,t}}{\sum_{j=1}^{N_r} s_{j,t}} \]
\[ P_i = \frac{1}{T} \sum_{t=1}^{T} s'_{i,t} \]
\(f_i\)는 시퀀스 T의 모든 토큰 \(t\)들에 대하여 전체 \(N_r\)개 expert에 대해 \(i\)번째 expert이 선택되는 비율을 나타내며, \(P_i\)는 \(i\)번째 expert가 전체 시퀀스에 대해서 얼마나 높은 유사도를 보였는지를 전체 시퀀스의 토큰들에 대하여 선택 확률의 평균을 내어 구했다.
모든 expert에 대해 \(f, P\)를 서로 곱해 더한 뒤 아주 작은 값의 하이퍼파라미터 \(\alpha\)와 곱해져 기존 language model의 loss에 더해 토큰들이 고르게 퍼지도록 만든다.
2.3.4. 노드 제한 라우팅
DeepSeek-V2에서 활용된 DeepSeekMoE는 여러 개의 디바이스(GPU)에 분할되어 지정된 각 expert가 각 디바이스에 올라가게 된다.
MoE는 결국 각 expert를 통과한 값을 Weighted sum 해버리는 것이기 때문에, 이렇게 디바이스가 쪼개진 상태에서는 communication 과정에서 병목이 생길 수 있다.
디바이스 제한 라우팅은 이를 방지하기 위해, 가장 연관도가 많은 expert를 가진 상위 \(M\)개(연관도 점수의 합으로 구한다) 디바이스에서만 처리될 수 있게 만든다.
노드 제한 라우팅 또한 비슷하게, 미리 지정해둔 \(M\)개의 상위 노드 에서만 expert를 활용하도록 제한하는 방식이다.
2.4. Multi-Token Prediction
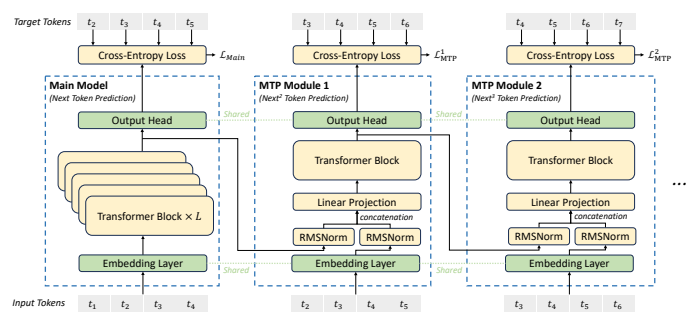
추가적으로, DeepSeek-V3은 Multi-Token Prediction 목표를 활용한다. 이는 단순히 한번에 한 토큰을 자기회귀적으로 생성하는 방식에서 벗어나, 미래 토큰 \(D\)개를 추가적으로 더 예측하는 것이다. 이 방법을 활용하게 되면 메인 모델이 추가로 \(D\)개의 토큰을 미리 계획할 수 있어서, 성능 증진에 도움이 된다고 한다.
2.4.1. MTP 모듈 구조
딥시크-V3은 미리 예측하고 싶은 토큰의 갯수 D만큼 모듈을 Sequential하게 적층해 D개의 토큰을 예측하도록 한다.
k번째 모듈은 메인 트랜스포머 모델과 공유하는 임베딩 레이어 \(\text{Emb}(\cdot)\), 또 같이 공유하는 출력 헤드 \(\text{OutHead}(\cdot)\)와 별도의 트랜스포머 블록 \(\text{TRM}(\cdot)\) , 그리고 프로젝션 행렬 \(M_k \in \mathbb{R}^{d\times 2d}\)로 구성되어있다.
모듈은 제공한 이미지에 기술된 방법과 동일하게 작동된다. 시퀀스 길이를 s, 각 토큰을 \(t_i, t_i\)의 hidden state를 \(h_i\)로 두면, 처음 메인 모델에 들어가는 토큰은 다음과 같다:
\([t_1, t_2, t_3, …, t_s]\)
이때, 메인 모델은 이 시퀀스를 바탕으로 \(t_{s+1}\)을 생성하고, \(\text{OutHead}(\cdot)\)의 입력값은 \([h_1, h_2, …, h_s]\) 이다.
첫번째 \(\text{MTP}\) 모듈은 \([h_1, h_2, …, h_s]\)와 \([t_2, t_3, …, t_{s+1}]\)를 입력받아 이 둘에 \(\text{RMSNorm}\) 을 적용, 서로 concat 한다.
이 두개의 시퀀스는 서로 길이가 같으므로, 임베딩 차원을 \(d\)로 둔다면 concat 이후 차원은 \(2d\)가 된다.
이를 다시 원래 임베딩 차원으로 돌려놓기 위해서 \(M_k\) 행렬을 활용해 프로젝션 해주고, 이를 한개의 트랜스포머 블록 \(\text{TRM}\)에 입력하여 토큰 \(t_{s+2}\)를 생성하는 것이다.
이를 일반화 시키자면, \(k\)번째 \(\text{MTP}\) 모듈은 \(k-1\)번째 \(\text{MTP}\)를 거친 hidden state들과, \(t_{k+1}\) 부터 \(t_{s+k}\)까지의 시퀀스를 받아 토큰 시퀀스는 임베딩을 거치고,
hidden state는 바로 \(\text{RMSNorm}\)을 거쳐 임베딩 차원끼리 concat하면 원래의 2배가 되므로 다시 원래 차원 수로 돌리는 선형 프로젝션을 한 뒤, 한개의 트랜스포머 블록에 입력해서 다음 토큰을 예측하는 것을 \(\text{MTP}\) 모듈들이 순차적으로(Sequential)하게 하는 것이다.
첫번째로 넘어오는 hidden state가 이미 메인 트랜스포머 블록을 거쳐서, 별도의 추가 어텐션 compute가 많이 필요하지 않는다.
2.4.2. MTP 학습 목표
\(\text{MTP}\)를 사용한다 하더라도, 결국 학습시킬 때 목표는 기존 LM 학습과 크게 다르지 않다.
\[ \mathcal{L}^k_{\text{MTP}} = \text{CrossEntropy}(P^k_{2+k:T+1},t_{2+k}) = -\frac{1}{T} \sum^{T+1}_{i=2+k}\log P^k_i[t_i], \]
미리 예측한 토큰도 학습 데이터와 같은 것은 마찬가지이기에, \(k\)번째 \(\text{MTP}\) 모듈의 loss도 Cross-Entropy를 활용한다.
수학적으로는, \(k\)번째 \(\text{MTP}\) 모듈이 예측한 모든 토큰(\(k+2\) 부터 시작)의 음의 로그 우도를 더해 평균을 낸다.
\[ \mathcal{L}_{MTP} = \frac{\lambda}{D}\sum^D_{k=1}\mathcal{L}^k_{MTP} \]
이 loss를 모든 \(\text{MTP}\) 모듈에 대해 평균을 내고, 가중치 변수 \(\lambda\)를 곱한다.
\(\mathcal{L}_{MTP}\)는 DeepSeek-V3의 부가적 학습 목표로 사용된다.
2.4.3. 추론에서의 MTP
\(\text{MTP}\)의 목표는 D개의 토큰을 가벼운 \(\text{MTP}\) 모듈로 예측하는 것이다.
이때, \(\text{MTP}\) 모듈의 손실이 그 모듈만 적용되는 것이 아닌, 전체 DeepSeek-V3을 학습하는데도 활용되므로 메인 모델 또한 \(D\)개의 미리 예측한 토큰을 따라가거나 이를 약간 수정하는 형태로 학습이 된다. 즉, 별도의 프롬프팅 등이 없어도 \(D\)개의 토큰을 미리 예측하는 행동이 메인 모델에 학습되는 것을 기대할 수 있고, 이는 성능의 증가로 이어질 것이다.
따라서, 추론 단계에서는 \(\text{MTP}\) 모듈을 제거, 일종의 계획을 할 수 있는 메인 모델만 남겨 추론한다.
일부 서빙 환경에서는 속도가 중요한 경우가 있는데, 이 경우 역으로 \(\text{MTP}\) 모듈이 매 자기회귀 단계에서 \(D\)개의 토큰을 추가로 더 생성하는 방법도 사용할 수 있다.
한번에 1개씩만 생성하는 방식과 달리, \(D+1\)개의 새 토큰을 생성하는 방식.
3. 학습 인프라
TODO
Mixed precision 부분이 매우 궁금하나, NSA가 갑자기 나와서 이거 팔로업 하느라 천천히 업데이트될 생각입니다.
당장은 논문 구조를 옮겨놓기만 하겠습니다.
3.1. 컴퓨팅 클러스터
3.2. 학습 프레임워크
3.2.1. DualPipe
컴퓨팅 간 소통 overlap 방식 어쩌구 저쩌구
3.2.2. 효율적인 노드간 A2A 커뮤니케이션 커널
3.2.3. 최대한의 메모리 절약과 최소한의 오버헤드
RMSNorm 재컴퓨팅과 MLA Up-proj
CPU에서의 지수이동평균
공유 임베딩과 출력 헤드 for MTP